
Office: SEIEE Building, No.3, 526A
Dr. LIN, Yun (林云)
-
My research lies in automatic programming, explainable AI, and web/AI security.
- Automatic Programming:
- Requirement Compilation (code repository generation/editing): Compile and evolve complex specification into runnable software projects (ISSTA'26, OOPSLA'26, ASE'25, ISSTA'24, NeurIPS'23, EMNLP'22, FSE'15);
- Software Testing: Generate test cases for requirement and branch coverage (ISSTA'25, FSE'23, TDSC'22, ESEC/FSE'21, ISSTA'20, ICSE'20, ICSE'18);
- Software Debugging: Debugging process synthesis and root cause analysis (ICSE'26, ASE'24, ISSTA'24, ISSTA'22, ICSE'17, ASE'18, TSE'19, FSE'19);
- Explainable AI (and Its Applications): representation interpretation, training data attribution, and their applications.
- Web and AI Security:
- Web Misinformation: Detecting and explaining fake websites, emails, and SMSs, and monitoring the world phishing campaigns (USENIX Sec'25, USENIX Sec'24a, USENIX Sec'24b, USENIX Sec'23, USENIX Sec'22, USENIX Sec'21).
- AI Security: Defending prompt injection attacks on LLMs (CCS'26);
Research Works
AI-driven Code Edits
In practical code edits, an editing session can include multiple (ir)relevant edits to the code under edit, and the inference of the subsequent edits is non-trivial as the scope of its ripple effect can be the whole project.
We propose solutions to recommend code edits by discriminating the relevant edits, exploring their interactive natures, and estimating its ripple effect in the project. CoEdPilot orchestrates multiple neural transformers to identify what and how to edit in the project regarding both edit location and edit content. See more details can be referred to CoEdPilot and CCDemon.
Search/LLM-based Software Testing

Code implementation requires test code to validate its functionalities. We automate generating software tests based on SBST (search-based software testing, an introduction link for SBST when I was in NUS) for higher code coverage and LLM for incorporating more project-specific domain knowledge.
Some work can be referred to EvoObj and EvoIF. Both are developed upon EvoSuite.
AI-driven Program Debugging
We build tools to generate both the debugging process and the final bug location of a given program bug. Technically, we explore time-travelling debugging, i.e., record-and-replay debugging. Considering the program executiont trace as a highway, the fault-revealing step as the source, the root-cause step as the destination, we aim to synthesize the "travel" from the source to the destination on such a highway. The video shows that how our debugging agent travels along the trace towards the root cause.
Some work can be referred to Tregression and Microbat. More works are coming!
AI Model Analytics (Explinable AI) and Its Applications
We build interactive and visualized approach for debugging deep models. We record the training process of deep models and projects the high-dimensional classification landscape into a two-dimensional space. Users can view the training dynamics of the high-dimensional classification landscape in the low-dimensional space, as a visualized animation. We recommend user-interested training events in a human-in-the-loop manner, guiding the users to pinpoint the root cause of model bugs like misprediction.
Some work can be referred to DeepVisualInsight, Empirical Influence Function (training data attribution), DeepDebugger, TimeVis, . More works are coming!
Web Misinformation
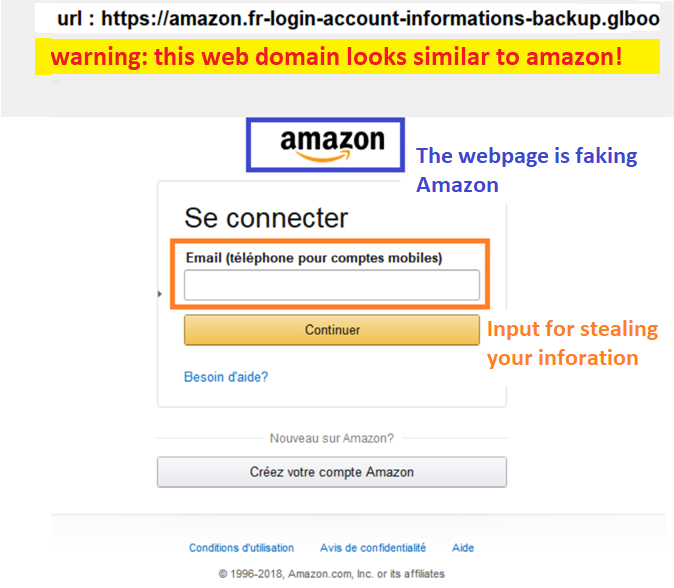
In the AIGC era, the fake website, email, and SMS are emerging with the advance of LLM application. We pioneer the deduction-based phishing detectors to fight the battle of misinformation, e.g., how the information of a webpage is inconsisistent so that the webpage must be phishing. Based on the approach, we further monitor the phishing campaigns, helping the security companies and govenments make more informed decision.
Some work can be referred to PhishDecloaker, PhishLLM, DynaPhish, PhishIntention, Phishpedia.